Высоконагруженные сайты, доступность "5 nines". На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g - означает "grid", распределенные вычисления. В основе распределенных вычислений "как ни крути" лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл - просто дать представление о технологии RAC.Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл - просто дать представление о технологии RAC.
Считаем, что кластер поднялся и все закрутилось.
Взаимодействие узлов. Cache-fusion.
Много экземпляров БД, много дисков. Хлынули пользовательские запросы… вот они, клиенты, которых мы так ждали. =)
Самым узким местом любой БД являются дисковый ввод-вывод. Поэтому все базы данных стараются как можно реже обращаться к дискам, используя отложенную запись. В RAC все так же, как и для single-instance БД: у каждого узла в RAM располагается область SGA (System Global Area), внутри нее находится буферный кэш (database buffer cache). Все блоки, некогда прочитанные с диска, попадают в этот буфер, и хранятся там как можно дольше. Но кэш не бесконечен, поэтому, чтобы оценить важность хранимого блока, используется TCA (Touch Count Algorithm), считающий количество обращений к блокам. При первом попадании в кэш, блок размещается в его cold-end. Чем чаще к блоку обращаются, тем ближе он к hot-end. Если же блок "залежался", он постепенно утрачивает свои позиции в кэше и рискует быть замещенным другой записью. Перезапись блоков начинается с наименее используемых. Кэш узла - крайне важен для производительности узлов, поэтому для поддержания высокой производительности в кластере кэшем нужно делиться (как завещал сами-знаете-кто). Блоки, хранимые в кэше узла кластера, могут иметь роль локальных, т.е. для его собственного пользования, но некоторые уже будут иметь пометку глобальные, которыми он, поскрипев зубами дисками, будет делится с другими узлами кластера.
Технология общего кэша в кластере называется Cache-fusion (синтез кэша). CRS на каждом узле порождает синхронные процессы LMSn, общее их название как сервиса - GCS (Global Cache Service). Эти процессы копируют прочитанные на этом экземпляре блоки (глобальные) из буферного кэша к экземпляру, который за ними обратился по сети, и также отвечают за откат неподтвержденных транзакций. На одном экземпляре их может быть до 36 штук (GCS_SERVER_PROCESSES). Обычно рекомендуется по одному LMSn на два ядра, иначе они слишком сильно расходуют ресурсы. За их координацию отвечает сервис GES (Global Enqueue Service), представленный на каждом узле процессами LMON и LMD. LMON отслеживает глобальные ресурсы всего кластера, обращается за блоками к соседним узлам, управляет восстановлением GCS. Когда узел добавляется или покидает кластер, он инициирует реконфигурацию блокировок и ресурсов. LMD управляет ресурсами узла, контролирует доступ к общим блоками и очередям, отвечает за блокировки запросов к GCS и управляет обслуживанием очереди запросов LMSn. В обязанности LMD также входит устранение глобальных взаимоблокировок в рамках нескольких узлов кластера.
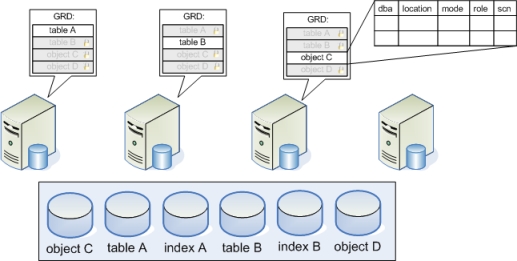
Но особая роль в координации ресурсов кластера и объединения кэша отведена таблице GRD (Global Resource Directory), в которой постоянно фиксируется, на каком экземпляре, какой блок (или его копия) доступен, режим, в котором экземпляр удерживает блок, роль блока, SCN. В single-instance варианте SCN - это просто инкрементный счетчик вносимых в БД изменений. В кластере же SCN необходимо синхронизировать между узлами. Существует два метода синхронизации SCN, в зависимости от значения параметра MAX_COMMIT_PROPOGATION_DELAY, задаваемого в миллисекундах:
- Если > 100, SCN генерируются (инкрементируются) на экземплярах параллельно. Эти SCN встраиваются в каждое сообщение, пересылаемое по interconnect, либо через определенные интервалы Oracle опрашивает экземпляры о текущих значениях SCN для взаимной синхронизации при простое. Обычно интервал составляет вплоть до 700 миллисекунд. Может использоваться при длительных транзакциях с "запоздалой" фиксацией.
- Если = 0 (default), то как только происходит COMMIT на каком-либо экземпляре, он тут же рассылает остальным оповещение о том, какой у него теперь номер. Обмен происходит очень часто (до долей секунд) и поэтому генерируется много трафика по interconnect.
В итоге SCN в RAC регулярно синхронизируются до самого большого SCN, известного в кластере. SCN требуется для того, чтобы записи о вносимых изменениях в блоках выстраивались в хронологическом порядке, что необходимо при восстановлении транзакций (roll-forward).
Таблица GRD распределена между узлами кластера. Каждый узел принимает участие в распределении ресурсов кластера, обновляя свою часть GRD. Часть таблицы GRD относится к ресурсам - объектам: таблицы, индексы и.т.п. Она постоянно синхронизируется (обновляется) между узлами.
Когда узел прочел блок данных с диска, он становится master-ом этого ресурса и делает соответствующую отметку в своей части таблицы GRD. Блок помечается как локальный, т.к. узел пока использует его в одиночку. Если же этот блок потребовался другому узлу, то процесс GCS пометит этот блок в таблице как глобальный ("опубликован" для кластера) и передаст затребовавшему узлу.
| DBA |
location |
mode |
role |
SCN |
PI/XI |
| 500 |
узел №3 |
shared |
local |
9996 |
Ok, let"s bring "em all together! В GRD у master узла, для координации распределения блоков между экземплярами кластера, с каждым блоком записывается дополнительная информация:
- Data Block Address (DBA): физический адрес блока
- Location: узел на котором доступен этот блок
- Resource mode: определяется тем, кто на текущий момент является владельцем блока и какая операция к нему будет применяться
- null: узел не претендует на изменение этого блока (только select)
- shared: к блоку осуществляется защищенный множественный доступ только для чтения на нескольких узлах.
- exclusive: узел собирается изменить (или уже изменил) этот блок. Хотя одновременно в кластере могут содержаться прежние (согласованные) версии этого же блока, менять их нельзя.
- Resource role: в каком режиме блок хранится в кэше узла
- local: когда узел только прочитал блок с диска, и ни с кем им еще не делился.
- global: когда узел был изначально считан этим блоком, но после был передан запросившему его узлу в некотором режиме (mode). Теперь этот же блок может присутствовать на других узлах.
- System Change Number (SCN): SCN в RAC, когда блок был изменен
- Image: характеризует копию блока, когда их одновременно несколько штук хранится в глобальном кэше всего кластера
- Past Image (PI): глобальный грязный блок (старая версия, после изменения), хранящийся в кэше узла после того, как узел передал его по сети другому. Блок держится в памяти пока он или более поздняя версия не будет записана на диск, о чем оповестит GCS, когда блок будет больше не нужен.
- Current Image (XI): текущая последняя копия блока, содержащаяся в последнем узле кластера в цепочке запросов этого блока.
Одни из самых важных принципов (single-instance) БД остаются верными и для RAC:
- как можно реже обращаться к диску, за счет активной работы с кэшем
- обеспечить consistency read (CR), согласованность по чтению, т.е. данные неподтвержденной транзакции никто никогда не увидит ни в какой (параллельной) сессии
Отличие среды RAC от обычного single-instance БД заключается в том, что блокировки, несмотря на все желание, осуществляются не на уровне строк, а на уровне блоков. Т.е. экземпляр может заблокировать целый блок (содержаний и другие кому-то нужные данные).
Опишем несколько типичных в жизни кластера ситуаций:
- Read/read behavior (no transfer).
Пусть данные таблицы A первым считал узел №4. Он является master этой таблицы и отвечает за соответствующую часть в GRD.
- На узел №3 пришел запрос на чтение из таблицы A. У узла №3 в кэше нет необходимого блока. Из GRD он узнает, что master таблицы A - это узел №4, и обращается к нему.
- Узел №4 просматривает GRD на наличие запрашиваемого блока. Если бы он был у него в кэше, то он просто бы передал его. Но допустим, что нужного блока не оказалось. Узел №4 отправит узлы №3 самостоятельно считать этот блок с диска.
- Узел №3 сам считывает его с диска, пока только для себя и ни с кем блоком не делится (local), но впоследствии может предоставлять к нему доступ другим узлам через посредника - master-а этой таблицы (shared).
- Узел №3 отчитывается перед master таблицы A узлом №4, и тот вносит соответствующую запись в GRD (на узле №4):
| DBA |
location |
mode |
role |
SCN |
PI/XI |
| 500 |
узел №3 |
shared |
local |
9996 |
0 (XI) |
- Read/read behavior (transfer).
- Пусть теперь запрос на чтение этого же блока пришелся на узел №2. Узел №2 знает из своей локальной копии GRD, что за этот ресурс (таблицу А) отвечает master узел №4 и обращается к нему.
- Узел №4 по своей таблице GRD узнает, что блок сейчас находится на узле №3 и передает ему указание поделиться блоком с узлом №2 в режиме для чтения.
- Узел №3, получив такую команду, передает копию блока узлу №2. В заголовке сообщения он также указывает, что делится копией, и у себя так же оставляет копию этого блока.
- Узел №2 получает блок и через GCS оповещает master узел №4 о том, что он получил нужный блок. Master обновляет GRD (узел №4):
| DBA |
location |
mode |
role |
SCN |
PI/XI |
| 500 |
узел №2 |
shared |
local |
9996 |
0 (XI) |
| 500 |
узел №3 |
shared |
local |
9996 |
0 (XI) |
- Read/Write behavior.
Наконец, пользователь решил внести изменения в таблицу А, касающиеся блока. Пусть пользователь подключен к узлу №1.
- Узел №1 посылает запрос на exclusive режим для блока master узлу №4.
- Узел №4 посылает сообщение всем узлам, удерживающим блок, кроме какого-то одного (допустим это узел №3), чтобы те перевели блок в полностью локальный режим (null mode, local role). Он перестает находиться в глобальном кэше, с него снимаются блокировки (его теперь можно будет перезаписать) и в кэше он пока хранится только для consistent read запросов.
- master запрашивает один из узлов (узел №3), передать этот блок в exclusive mode узлу №1.
- Узел №3 пересылает блок узлу №1, с указанием того что блок передается в exclusive mode, а следовательно его собственный будет снят из глобального кэша. Узел №3 снимает блокировки с блока (его теперь можно будет перезаписать), оставляя его в кэше только для consistent read запросов.
- Запрашивающий узел №1 наконец-то получает свой блок, вносит необходимые изменения, назначает новый SCN. Уведомляет master узел №4 о том, что блок получении и изменен, дополнительно сообщение включает информацию о том, что узел №3 у себя закрыл этот блок.
- Узел №4 подтверждает вычеркивание блока для узла №3. И теперь GRD на узле №4 содержит:
| DBA |
location |
mode |
role |
SCN |
PI/XI |
| 500 |
узел №1 |
shared |
local |
10010 |
0 (XI) |
- Write/Write behavior.
Пусть теперь одновременно нужно произвести обновления в блоке в таблице A. Master-ом ресурса выступает всегда один узел, и GCS (Global Cache Service) на нем действуют последовательно, используя механизмы блокировок ресурса:
- Пришел запрос на update на узел №2, который уже убрал этот блок из глобального кэша. Узел заново обращается к master узлу c запросом на exclusive mode на блок.
- Узел №4 запрашивает текущего держателя блока выдать узлу №2 образ (current image) блока.
- Узел №1, после того как убедится, что redo журналы с примененными изменениями к блоку были сброшены на диск (важно: транзакция на нем может все еще продолжать выполняться!), переводит образ своей копии в past image (ведь узел №2 внесет в него изменения), которую он теперь не сможет модифицировать. И пересылает блок в exclusive mode запрашивающему узлу №2, дополнительно включая в сообщение, что он теперь держит PI блока.
- Запрашивающий узел №2 получает блок, вносит необходимые изменения, назначает новый SCN. Уведомляет master узел №4 о том, что блок получении и изменен, дополнительно сообщение включает информацию о том, что узел №2 держит блок в exclusive mode, а блок №1 содержит его прежнюю версию (SCN = 10010).
- Узел №4 вносит изменения в GRD:
| DBA |
location |
mode |
role |
SCN |
PI/XI |
| 500 |
узел №1 |
shared |
global |
10010 |
1 (PI) |
| 500 |
узел №2 |
exclusive |
local |
10016 |
0 (XI) |
- Write/Read behavior.
Иная ситуация: блок был изменен в каком-то из узлов и теперь последняя версия достаточно сильно отличается от той, что хранится на диске.
- Пришел запрос на select из таблицы А узлу №3, он обращается к master ресурса.
- Master узел из GRD выясняет, что последняя версия блока содержится на узле №2 и направляет туда запрос передать блок узлу №3.
- На узле №2 блок был получен и хранился в exclusive mode. Как только работа с блоком прекращается, узел №2 переводит его в shared mode, свою копию блока помечает как past image (SCN=10016) и передает ее узлу №3.
- Узел №4 вносит изменения в GRD:
| DBA |
location |
mode |
role |
SCN |
PI/XI |
| 500 |
узел №1 |
shared |
local |
10010 |
1 (PI) |
| 500 |
узел №2 |
shared |
global |
10016 |
1 (PI) |
| 500 |
узел №3 |
shared |
global |
10016 |
0 (XI) |
- Write-to-disk behavior.
Допустим, подошло время сбрасывать данные на диск. Оно всегда наступает, как его не оттягивай:
- количество грязных данных в буфере перевалит за некоторое значение (порог). Необходимо записать эти измененные данные, для того чтобы освободить буфер, и в него можно было внести что-то новенькое
- когда в буфере заканчивается свободное пространство
- DBWR регулярно сбрасывает измененные данные с буфера на диск (LOG_CHECKPOINT_TIMEOUT).
- Кстати, это можно контролировать и через другой параметр: fast_start_mttr_target = 3 sec (default), который определяет частоту прохождения checkpoint, т.е. как часто будут сбрасываться на диск (flush) записи, накопившиеся в redo log buffer и buffer cache. Это нужно для того, чтобы восстановление транзакций узла (roll-forward), в случае сбоя, заняло примерно 3 секунды.
- Допустим, узел №1 с устаревшим блоком, собирается его записать на диск, он обращается к master ресурса узлу №4, предоставляя SCN своего блока.
- Узел №4 узнает по GRD, что последнюю версию держит узел №2. Он обращается к нему, чтобы узел №2 осуществил запись на диск.
- Пока узел два будет производить запись на диск, никто не сможет изменять блок. Им придется постоять в очереди у GRD. Так происходит с общими shared блоками (устаревшие и локальные можно выкинуть и не принимать во внимание).
- Узел №2 записывает данные на диск.
- Узел №2 оповещает master о том, что данные записаны на диск. Его блок переходит в local role (только у него, останется этот блок).
- Получив такое сообщение GCS посылает сигнал по всем узлам отчистить свои PI, и если кто-то держал блок с exclusive mode переключается в local role.
- Теперь же этот блок можно будет читать с диска, либо же обращаться к узлу содержащему его в памяти.
Без необходимости никаких записей на диск не происходит. Всегда копия блока хранится на узле, на котором он чаще используется. Если определенного блока пока еще нет в глобальном кэше, то при запросе master попросит соответствующий узел прочитать блок с диска и поделиться им с остальными узлами (по мере надобности).
Исходя из описанного выше, становится ясно, что cache-fusion предполагает 2 сценария:
- Участвует 2 узла: когда целевому узлу потребовался блок, который хранился в кэше master.
- Участвует 3 узла: когда master отправляет запрос промежуточному узлу, и тот передает блок востребованному в нем узлу.
Неважно, сколько в кластере узлов, количество хопов (узлов, принимающих участие в пересылке блока) никогда не превысит 3. Этот факт и объясняет способность кластера RAC безболезненно масштабироваться на большое количество узлов.
Taking fire, need assistance! Workload distribution.
Описанное устройство Cache-fusion, предоставляет кластеру возможность самому (автоматически) реагировать на загрузку узлов. Вот как происходит workload distribution или resource remastering (перераспределение вычислительных ресурсов):
Если, скажем, через узел №1 1500 пользователей обращается к ресурсу A, и примерно в это же время 100 пользователей обращается к тому же ресурсу A через узел №2, то очевидно, что первый узел имеет большее количество запросов, и чаще будет читать с диска. Таким образом узел №1 будет определен как master для запросов к ресурсу A, и GRD будет создано и координироваться начиная с узла №1. Если узлу №2 потребуются те же самые ресурсы, то для получения доступа к ним он должен будет согласовать свои действия с GCS и GRD узла №1, для получения ресурсов через interconnect.
Если же распределение ресурсов поменяется в пользу узла №2, то процессы №2 и №1 скоординируются свои действия через interconnect, и master-ом ресурса A станет узел №2, т.к. теперь он будет чаще обращаться к диску.
Это называется родственность (affinity) ресурсов, т.е. ресурсы будут выделяться тому узлу, на котором происходит больше действий по получению и их блокированию. Политика родственности ресурсов скоординирует деятельность узлов, чтобы ресурсы более доступны были там, где это более необходимо. Вот, кратко, и весь workload distribution.
Перераспределение (remastering) также происходит, когда какой-то узел добавляется или покидает кластер. Oracle перераспределяет ресурсы по алгоритму называемому "ленивое перераспределение" (lazy remastering), т.к. Oracle почти не принимает активных действий по перераспределению ресурсов. Если какой-то узел упал, то все, что предпримет Oracle - это перекинет ресурсы, принадлежавшие обвалившемуся узлу, на какой-то один из оставшихся (менее загруженный). После стабилизации нагрузки GCS и GES заново (автоматически) перераспределят ресурсы (workload distribution) по тем позициям, где они более востребованы. Аналогичное действие происходит при добавлении узла: примерно равное количество ресурсов отделяется от действующих узлов и назначается вновь прибывшему. Потом опять произойдет workload distribution.
Как правило, для инициализации динамического перераспределения, загруженность на определенном узле должна превышать загруженность остальных в течение более 10 минут.
Вот пуля пролетела, и… ага? Recovery.
Вдруг какой-то узел не ответил на heartbeat, процесс CSSD на узле, который первым это обнаружил, "бьет тревогу" и докладывает master узлу (если тот еще на связи, в противном случае придется самому брать на себя обязанности master"a). Master инициирует на всех узлах процедуру "голосования", уцелевшие узлы кластера начинают отмечаться на voting disk. Если пропавший узел и тут не оставляет следов, то master начинает процесс исключения пропавшего из кластера. Redo log файл будет читаться дважды: один раз по записям redo, в второй раз (заново) уже по записям undo, чтобы сделать базу доступной для запросов как можно раньше.
- Часть GRD таблицы с ресурсами упавшего узла "замораживается".
- Не вышедший на связь узел помечается как "пропавший", чтобы оставшиеся узлы к нему не обращались зря по interconnect.
- Узел, который первым обнаружил пропажу, начинает восстановление информации, которая обрабатывалась на исчезнувшем узле:
- Понижает темпы обслуживания собственных транзакций, бросая вычислительные ресурсы на восстановление
- Обращается к общему файловому хранилищу (datastorage), и на себе начинает применять online redo logs, принадлежавшие пропавшему узлу. С учетом порядкового номера SCN блоков, merge их с тем, что хранится в буфере, и "накатывает" (roll-forward) в своем кэше. При этом узел пропускает те устаревшие записи блоков (PI), более поздние версии которых, уже были сброшены на диск. Если у считанных блоков в кластере присутствует master соответствующего ресурса, то узел сообщает список считанных блоков, и master на этих ресурсах выставляет блокировку, чтобы узлы к ним не обращались (пока они восстанавливаются).
- После чего, вторым прочтением по redo log, учитывая уже undo записи, откатывает (roll-back) незафиксированные транзакции. Происходит это по технологии fast-recovery, т.е. откат транзакций будет производиться отдельным background процессом. Oracle вернет заблокированные незавершенными транзакциями (uncommitted) блоки в согласованное состояние (consistent), к прежним значениям, как только придет запрос на эти блоки. Либо они уже к тому времени будут восстановлены этим самым параллельным background процессом. Таким образом, уже в кластере снимаются блокировки и могут выполняться новые запросы пользователей.
- Часть таблицы GRD, принадлежавшая упавшему узлу, размораживается на восстанавливающем узле (теперь он master ресурса). Таким образом, в кластере восстанавливается состояние обрабатываемых транзакций на пропавшем узле на момент "падения".
Но пока все эти процессы происходят, нетерпеливому клиенту есть что предложить.
Пока узлы спасают друг друга… Failover.
Failover - это обработка ситуации сбоя узла в кластере.
Самое время упомянуть еще один слой в кластерной среде - общедоступная (public) сеть, через которую клиенты обращаются к базе данных. На физических серверах желательно не менее 2-х сетевых карт:
- Первой сетевой карте присваивается статический IP, через который узел будет обмениваться сообщениями со своими соседями в кластере (interconnect).
- Второй сетевой карте назначается логический Virtual IP (виртуальный IP), через который клиенты будут отправлять запросы на узел кластера.
Virtual IP (VIP) - логический сетевой адрес, назначаемый узлу на внешнем сетевом интерфейсе. Он предоставляет возможность CRS спокойно запускать, останавливать и переносить работу с этим VIP на другой узел. Listener (процесс, принимающий соединения) на каждом узле будет прослушивать свой VIP. Как только какой-то узел становится недоступным, его VIP подхватывает на себя другой узел в кластере, таким образом, временно обслуживая свои и запросы упавшего узла.
Это делается для того, чтобы снизить время простоя клиента в случае, если узел, на котором осуществлялась его транзакция, отвалился. Ведь клиент может ожидать TCP timeout в течение нескольких минут. В данном же случае, VIP тут же "подхватится" другим узлом и дальше события могут развиваться по двум сценариям, по технологии TAF (Transparent Application Failover):
- Database VIPs: Клиент подсоединится по VIP, но уже подключится к другому узлу. Временно замещающий узел ответит "logon failed", несмотря на то, что VIP будет active, нужный экземпляр БД за ним будет отсутствовать. И клиент тут же повторит попытку, но уже к другому экземпляру/узлу кластера из своего списка в конфигурации.
- Application VIP: то же, что и прежде. Но только теперь по этому VIP можно будет обратиться к приложению, на каком бы узле оно ни крутилось.
Database VIP могут предоставлять приложения только своего узла, и если приложение мигрировало, то отвечают отказом. Application VIP даже после миграции выполняет предоставляемый узлом функционал (positive).
Если узел восстановится и выйдет в online, CRS опознает это и попросит сбросить в offline на подменяющем его узле и вернет VIP адрес обратно владельцу. VIP относится к CRS, и может не перебросится если выйдет из строя именно экземпляр БД.
Важно отметить, что при failover переносятся только запросы select, вместе и открытыми курсорами (возвращающими результат). Транзакции не переносятся (PL/SQL, temp tables, insert, update, delete), их всегда нужно будет запускать заново.
Есть два способа конфигурации TAF:
- Connect-time failover and client load-balancing
В этом случае клиент всегда случайно выбирает к какому узлу кластера подключиться из своего списка конфигурации сетевого подключения. Если узел, выполняющий запрос, выходит из строя, то по TAF клиент выбирает другой узел кластера и переподключается.
- Preconnect
В этом случае, клиент всегда при установлении соединения с кластером подключается ко всем узлам, хотя запрос будет запускать только на одном экземпляре. Если же узел выходит из строя, то просто переводит запрос на другой узел. Failover происходит быстрее, но расходует ресурсы на подключение на всех узлах кластера.
У клиентского подключения есть параметры retries и delay. Ими можно настраивать, сколько раз клиент (молча) попробует переподключиться в случае, если узел упадет, и какую задержку выставить. Пожалуй, самое интересное - это то, что в случае падения узла, Oracle может об этом оповестить клиента через FAN (Fast Application Notification), который является частью ONS (Oracle Notification Services). Если клиент использует "толстый" драйвер подключения к Oracle, то перед обращением к базе данных можно зарегистрировать callback функцию (обратного вызова), на которую придет event, в случае TAF (failover). Это можно либо отобразить как "небольшую заминку" у пользователя на экране и контролировать процесс перезапуска запроса вручную.
Туда не ходи, сюда ходи… Load-balancing.
При выполнении любых операций, информацию, относящуюся к производительности запросов (наподобие "отладочной"), Oracle собирает в AWR (Automatic Workload Repository). Она хранится в tablespace SYSAUX. Сбор статистики запускается каждые 60 минут (default): I/O waits, wait events, CPU used per session, I/O rates on datafiles (к какому файлу чаще всего происходит обращение).
Необходимость в Load-balancing (распределении нагрузки) по узлам в кластере определяется по набору критериев: по числу физических подключений к узлу, по загрузке процессора (CPU), по трафику. Жаль что нельзя load-balance по среднему времени выполнения запроса на узлах, но, как правило, это некоторым образом связано с задействованными ресурсами на узлах, а следовательно оставшимися свободными ресурсам.
О Client load-balancing было немного сказано выше. Он просто позволяет клиенту подключаться к случайно выбранному узлу кластера из списка в конфигурации. Для осуществления же Server-side load-balancing отдельный процесс PMON (process monitor) собирает информацию о загрузке узлов кластера. Частота обновления этой информации зависит от загруженности кластера и может колебаться в пределе от приблизительно 1 минуты до 10 минут. На основании этой информации Listener на узле, к которому подключился клиент, будет перенаправлять его на наименее загруженный узел.
Oracle предоставляет DBA выбирать наиболее значимые критерии для балансировки нагрузки:
- Based on elapsed-time (CLB_GOAL_SHORT): по среднему времени выполнения запроса на узле
- Based on number of sessions (CLB_GOAL_LONG): по количеству подключений к узлу
Если в приложении реализован connection pool, Oracle предоставляет вариант Runtime Connection Load Balancing (RCLB). Вместо обычного варианта, когда мы пытаемся предугадать, который из узлов будет менее загружен, и направить запрос туда, будет использован механизм оповещений (events) приложения о загрузке на узлах. И теперь уже само приложение будет определять куда отправить запрос, опираясь на эти данные. Оповещение происходит через ONS (Oracle Notification Service). RCLB регулярно получает данные (feedback) от узлов кластера, и connection pool будет раздавать подключения клиентам, опираясь на некоторое относительное число, отображающее какой процент подключений каждый экземпляр может выполнить. Эти метрики (средняя загрузка узла), которые пересылает RAC, каждый узел строит сам в AWR. На их основании формируется required load advisory и помещается в очередь AQ (advanced querying), откуда данные пересылаются через ONS клиенту.
Уведомления будут строиться по одному из механизмов:
- С упором на временные задержки выполнения запросов (GOAL_SERVICE_TIME)
Учитываются временные задержки обработки предыдущих запросов.
- С упором на нагрузку на сервер (GOAL_THROUGHPUT)
Учитывается пропускная способность и загруженность CPU
Окончание.
Ссылки по теме
